What are IP address classes? Importance for VPNs and cybersecurity



Every device that connects to the internet needs an address that identifies it on the network. Internet Protocol (IP) address classes were created to organize those addresses and decide how many could be used within each network. The system was later superseded by a classless model, which allocates address blocks more efficiently.
Nonetheless, the logic behind the IP class structure still shapes how modern networks are organized. It influences how virtual private networks (VPNs) assign private addresses, how traffic is separated inside organizations, and how communication stays secure between connected systems.
This article looks at what IP address classes are, how they work, and why the idea behind them continues to matter for VPNs, privacy, and modern network design.
What is an IP address?
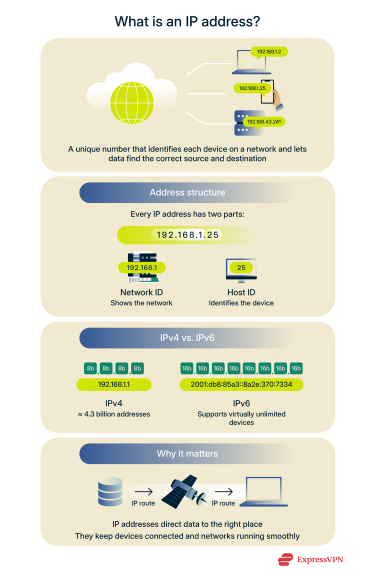 An IP address is a unique number assigned to any device that connects to the internet or to a private network that uses the Internet Protocol. It identifies the source and destination of data packets, allowing systems to exchange information across a network or the internet.
An IP address is a unique number assigned to any device that connects to the internet or to a private network that uses the Internet Protocol. It identifies the source and destination of data packets, allowing systems to exchange information across a network or the internet.
There are two versions of the Internet Protocol currently in use: IPv4 and IPv6. IPv4 addresses are built on the binary system and contain 32 bits in total. They’re divided into four sections called octets, each containing 8 bits. In a human-readable form, these octets are written as decimal numbers separated by periods, a format known as dotted-decimal notation.
Each octet can have a value from 0 to 255, because 8 bits can represent 256 different combinations (2⁸ = 256). An example IPv4 address looks like this:
192.168.43.241
Behind the scenes, computers process these numbers in binary form. The same address above would appear as:
- 192 → 11000000
- 168 → 10101000
- 43 → 00101011
- 241 → 11110001
So, in binary, 192.168.43.241 is written as 11000000.10101000.00101011.11110001.
This design provides around 4.3 billion unique addresses. Early implementations grouped them into fixed categories called classes to simplify how networks were organized and routed.
Each IP address has two sections: one specifies the network, and the other identifies the device (host) within it. This structure keeps data flowing to the right destination and prevents duplicate addresses from causing routing errors inside or between networks.
IPv6 extends the IP address size to 128 bits and writes it in hexadecimal separated by colons: for example, 2001:db8:85a3::8a2e:370:7334. The increase in size creates an immense number of possible addresses (around 340 undecillion), supporting the continued expansion of the internet.
Both versions serve the same role: they assign each device a unique identity so information can be delivered accurately between networks. Although the global pool of IPv4 addresses has been exhausted, IPv4 is still the primary standard for most internet and network communications today. IPv6 adoption is growing, but the two protocols continue to coexist as the transition progresses.
See also: Difference between static and dynamic addresses
The 5 classes of IP addresses
When IPv4 was first introduced, its entire address space was divided into five IPv4 address classes: A, B, C, D, and E. Each class specified how many networks could exist and how many individual hosts each network could contain. This system gave early network engineers a predictable way to assign addresses and to connect networks of different scales without overlap. This structure became known as classful IP addressing.
In the class-based system, the IPv4 32-bit structure was divided into fixed portions for the network and the host. Class A networks reserved the first 8 bits for the network portion, Class B used 16, and Class C used 24. This is commonly shown in prefix form (/8, /16, or /24) or as a default subnet mask, such as 255.0.0.0 for Class A.
This design made address allocation predictable in the early days of the internet: large organizations received Class A blocks, mid-sized networks received Class B, and smaller ones received Class C. Classes D and E were reserved for special uses: multicasting and experimental purposes.
Although classful addressing is no longer used for assigning new IP blocks, it still helps explain how IPv4 networks are organized today. Modern systems rely on Classless Inter-Domain Routing (CIDR) for allocation and routing, but the original class ranges continue to influence private address spaces. Request for Comments (RFC) 1918, which defines private IP ranges, draws from the old Class A, B, and C blocks.
| Class | First address | Last address | Default mask | Typical use |
| A | 0.0.0.0 | 126.255.255.255 | 255.0.0.0 (/8) | Very large networks (historic) |
| B | 128.0.0.0 | 191.255.255.255 | 255.255.0.0 (/16) | Medium networks (historic) |
| C | 192.0.0.0 | 223.255.255.255 | 255.255.255.0 (/24) | Small networks (historic) |
| D | 224.0.0.0 | 239.255.255.255 | n/a | Multicast |
| E | 240.0.0.0 | 255.255.255.254 | n/a | Experimental |
Class A
A Class A IP address network was created for very large networks such as government departments, major telecom providers, and early internet backbone operators. It spans 1.0.0.0 to 126.255.255.255 and uses a /8 prefix, meaning the first 8 bits identify the network as explained above. The default mask is 255.0.0.0.
A single Class A network could hold over 16 million individual addresses, which suited the large government, academic, and telecom systems that dominated the early internet. Today, these massive blocks are no longer kept as one piece. They’re split into smaller subnetworks to make routing more efficient and to simplify how addresses are managed.
Class B
Class B IP address networks were meant for mid-sized organizations such as universities, large companies, and regional internet providers. Their address range runs from 128.0.0.0 to 191.255.255.255, using a /16 prefix and the default subnet mask 255.255.0.0.
Each Class B block provides about 65,000 usable addresses, which is enough for complex internal systems but is still practical to administer. This balance made Class B one of the most widely issued categories in the early days of the internet.
Class C
Class C IP address networks were created for smaller setups such as offices, residential networks, and branch locations. Their range spans 192.0.0.0 to 223.255.255.255 and uses a /24 prefix with a default mask of 255.255.255.0.
Each Class C block supports up to 254 devices. These smaller allocations were efficient for local environments and remain the standard for home and small business networks.
Class D
Class D IP addresses are reserved for multicast, which lets one sender deliver the same data stream to many receivers. In contrast, unicast delivers data from one sender to one receiver only.
This address range runs from 224.0.0.0 to 239.255.255.255. Devices that want to take part in a multicast session join a multicast group and receive whatever data the source transmits to it. Multicast is used in streaming, conferencing, and other real-time applications that need to send identical information to multiple endpoints efficiently.
Class E
Class E IP addresses cover the range 240.0.0.0 to 255.255.255.254 and were set aside for research and experimental use. These addresses aren’t routed on the public internet, and most current systems simply ignore them for normal communication.
While several draft proposals have suggested repurposing Class E (240.0.0.0/4) to ease IPv4 address exhaustion, the Internet Assigned Numbers Authority (IANA), which manages the global allocation of IP addresses, continues to reserve Class E for non-standard or experimental use.
Special IP address ranges
Not every IPv4 address is meant for public use. Some are reserved for internal communication, testing, or automatic configuration. These special ranges make it possible for devices to function and communicate reliably even without direct access to the wider internet.
Reserved IP addresses
Certain address blocks are set aside for private networks and can’t be used on the public internet. These come from the traditional Classes A, B, and C and are defined in RFC 1918.
- 10.0.0.0–10.255.255.255 (Class A range): This block is often used in large organizations or data centers where thousands of devices share the same internal network. Because of its size, it allows flexible subnetting for multiple departments or divisions.
- 172.16.0.0–172.31.255.255 (Class B range): This range suits medium-sized networks, such as university campuses or large enterprises. It balances capacity and manageability, supporting tens of thousands of connected devices.
- 192.168.0.0–192.168.255.255 (Class C range): This range is widely used in home and small office routers. Addresses like 192.168.0.1 or 192.168.1.1 are common defaults for local gateways that connect private devices to the internet.
Devices that use private IPs can’t be reached directly from the internet. When they need to access external sites, routers translate those private addresses into public ones using a process called Network Address Translation (NAT).
This allows many devices to share a single public IP, conserving address space while keeping internal addresses hidden.
Loopback addresses
The 127.0.0.0–127.255.255.255 block is reserved for what’s called the loopback interface: a virtual network connection a device uses to send data to itself.
The most familiar address in this range is 127.0.0.1, which simply points back to the same device. Any data sent to it stays inside the system instead of going out over a network.
This setup gives developers and administrators a safe way to test software, services, and network settings without involving external connections. For instance, a web server running on your own computer can be opened in a browser by visiting 127.0.0.1.
Automatic Private IP Addressing (APIPA)
If a device can’t get an IP address from a Dynamic Host Configuration Protocol (DHCP) server (a network system that normally assigns them), it will generate one for itself from the 169.254.0.0 to 169.254.255.255 range. This is known as Automatic Private IP Addressing (APIPA).
APIPA allows devices within the same local subnet to communicate when no router or DHCP server is available: for instance, two computers connected to the same switch or wireless access point. These addresses are limited to local traffic and can’t reach the internet.
When a DHCP server becomes available again, the device releases its APIPA address and uses the one assigned by the network. If the device fails to obtain a new IP address after the DHCP server becomes available, it may remain on its self-assigned APIPA address and show a “no network connection” or “no internet access” error.
IP address classes and security in VPNs
The way IP addresses are organized still matters for a VPN. It decides how devices are grouped, how traffic moves inside the network, and how private addresses stay separate from the public internet.
Why VPNs rely on private IP addresses
When a device connects to a VPN, it’s assigned a private IP address that exists only within that network. The address is usually taken from the RFC 1918 ranges, which aren’t routed on the public internet.
Once assigned, the VPN establishes an encrypted tunnel between your device and its server. All traffic moves through that tunnel, keeping your real IP address and internal network details out of view while crossing public networks.
The server, on the other hand, communicates with external websites through its own public IP. This separation between private and public addressing keeps user devices off the open internet and conceals how the internal network is structured.
In many corporate VPN setups, segmentation is built in. Administrators can allocate distinct subnets to different users, departments, or remote offices, then apply separate firewall, Domain Name System (DNS), or IP whitelisting rules to each. Doing so limits what each segment can see and keeps data confined to the groups that should have access.
IP address classes and online privacy
Websites and online services can see the public IP address that your connection uses. From that address, they can often tell your general location and the provider handling your traffic. A VPN replaces that visible IP with the address of its own server, so the site sees the VPN server’s IP address instead of yours.
Private address ranges, which came from the old IP class model, also play a part in privacy. Devices that use them sit behind routers or VPN gateways that run NAT. Because of that, outside systems don’t see the internal layout; every request appears to come from the VPN’s public endpoint.
Modern VPNs add extra protection by rotating their server IP addresses, stopping DNS or IPv6 leaks, and blocking any backup routes that might expose a user’s real location. In effect, the VPN sits on top of the public internet as a private network layer that keeps identity and data secure while traffic moves through it. These network-level protections align with broader network security standards used across modern organizations.
Subnetting and its relationship to IP classes
The class-based structure made address allocation predictable but inflexible. For example, if you were an organization that needed 500 IP addresses, you couldn’t use a class C address, as that would only give you 254 addresses. So instead, you’d have to go for a class B IP with 65,000 addresses, giving you 64,500 addresses you’d never use.
Subnetting was introduced to make those rigid class boundaries flexible. Instead of treating an entire Class A or B as a single block, subnetting allows administrators to divide it into smaller, logical segments, each with its own range of IP addresses and internal routing rules. These smaller networks, or subnets, can then be routed and secured independently, improving both efficiency and control.
What is subnetting?
Subnetting divides a single IP network into smaller, structured parts. Each subnet operates independently inside the main network and connects to other subnets through a router or gateway.
It works by taking bits from the host portion of an IP address and using them to extend the network portion. This defines how many subnets exist and how many devices each one can hold.
Say a company has the block 172.16.0.0/16. It can divide that into several /24 networks, each with room for 254 devices. The address space doesn’t grow (and it only shrinks negligibly with the introduction of a new broadcast and network address for each network). Breaking it up this way keeps routing simpler and security policies easier to apply.
Subnet vs. subnet mask
The terms “subnet” and “subnet mask” are related, but they serve different purposes:
- Subnet mask: The subnet mask is the mechanism that makes subnetting possible. It’s a 32-bit pattern that tells devices which part of an IP address refers to the network and which part refers to the host.
- Bits set to 1 mark the network portion.
- Bits set to 0 mark the host portion.
When a device compares its own IP address with a subnet mask, it can tell whether another address is part of the same subnet or needs to be routed outside it.
- Subnet: A subnet is the result of subnet masking. It’s a smaller, independent segment of a larger IP network. Each subnet has its own address range, broadcast address, and often its own routing or access rules. It defines where one logical network ends and another begins.
The same format works for networks of different sizes. A /24 mask (255.255.255.0) provides 256 total addresses, with 254 usable for hosts after reserving one for the network and one for broadcast. A /25 mask (255.255.255.128) divides that range into two subnets of 128 addresses each, allowing 126 usable hosts per subnet.
This ability to redefine boundaries dynamically is what makes subnetting so powerful.
Purpose and benefits of subnetting
Subnetting delivers operational efficiency and security advantages, including:
- Efficient use of addresses: Subnet sizes can match the number of devices on each segment, which prevents large portions of address space from going unused.
- Performance: Local traffic stays inside its own subnet, so broadcast noise is lower and routing stays lighter.
- Management: Dividing a network by purpose (say, separating office staff, guest Wi-Fi, and servers) makes organization and monitoring easier.
- Security: Traffic between subnets can be controlled. Firewalls or VPN gateways can stop threats from spreading beyond the area where they start.
- Troubleshooting: When a problem appears, it affects only that subnet; the rest of the network keeps running.
- Scalability: More subnets can be added later or merged when the network grows.
Practical subnetting examples
- Corporate segmentation: A company using a 172.16.0.0/16 block can divide it into multiple /24 subnets, such as 172.16.1.0/24, 172.16.2.0/24, and so on, assigning each department its own range and firewall policy. An internet service provider (ISP) with a 172.16.0.0/16 network can allocate 172.16.1.0/24, 172.16.2.0/24, and similar ranges to customers.
- Home and small office networks: Most consumer routers use 192.168.1.0/24 by default, supporting up to 254 connected devices in the 192.168.1.2–192.168.1.253 range. A /25 mask (255.255.255.128) can be used to split that space into two smaller subnets of 126 hosts each: one for work devices and another for guest connections. Users who need fixed local addresses for printers or servers can configure a static IP address through their router settings.
- VPN segmentation: Enterprise and open-source VPNs can assign unique subnets to different groups, sites, or users. This allows administrators to apply separate firewall rules for each subnet, keeping traffic isolated and routing simpler inside the VPN tunnel.
Are IP address classes still relevant today?
The class-based system helped organize early networks, but it isn’t used for address allocation anymore. It only helps in understanding how IPv4 is structured, not for modern routing or distribution.
Drawbacks of the class system
Class-based addressing was easy to implement, but it wasted a lot of space. The fixed ranges worked when the internet was small, then quickly ran into limits as networks grew.
Large address blocks were allocated to early government, academic, and corporate networks, while smaller organizations had to rely on the limited Class C range. Because each Class C network could hold only about 250 hosts, many small networks quickly ran out of available addresses.
Routing tables (the lists that tell routers where to send traffic) also became overloaded, since every individual network block had to be recorded separately, even when much of its address space wasn’t used.
Transition toward classless (CIDR) addressing
To solve these limitations, the internet shifted in the 1990s to Classless Inter-Domain Routing (CIDR). CIDR eliminates fixed class boundaries and lets address blocks be defined solely by prefix length (for example, 192.0.2.0/23).
This means organizations can receive address blocks sized more closely to their needs, and ISPs can group multiple smaller networks into a single routing entry through route aggregation.
CIDR also introduced flexibility in how address blocks could grow or shrink without being tied to the old A, B, and C limits. That’s because CIDR lets networks use variable prefix lengths instead of fixed class sizes. Each block could be defined with any prefix value; for example, /22 for about 1,000 addresses or /30 for just four. This method, known as variable-length subnetting, allowed organizations to assign address space that matched their actual needs instead of wasting unused addresses.
Today, CIDR notation is used universally in both IPv4 and IPv6 addressing. Although “class” terminology survives in some educational and legacy contexts, modern routing and allocation practices are based fully on CIDR addressing.
IPv6 and the future of addressing
CIDR extended the life of IPv4, but as mentioned earlier, its 32-bit space still ran out. IPv6 was created to solve that problem and to handle the scale of today’s internet. It uses 128-bit addresses, giving enough combinations that address exhaustion is no longer a concern.
IPv6 addressing was built around a classless, hierarchical model from the beginning. Networks can be divided or combined in any way that fits routing needs, from global providers to small local systems.
It also adds features that IPv4 never had, including automatic address configuration and native Internet Protocol Security (IPsec). What’s more, IPv6 uses multicast to send network messages only to the devices that need them instead of broadcasting to every device on the network. This is faster and reduces unnecessary traffic.
FAQ: Common questions about IP address classes
What are the 5 classes of IP addresses?
IPv4 addresses were originally divided into 5 categories: Class A, B, C, D, and E. Classes A through C supported networks of different sizes, while Class D was used for multicast, and Class E was reserved for research and testing. Each class determined how many networks and hosts could exist within its range.
What are private IP addresses?
Private IP addresses are blocks reserved for use inside local networks. Defined by Request for Comments (RFC) 1918, they include 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16. These addresses aren’t reachable on the public internet; routers translate them into a public IP through Network Address Translation (NAT) when devices connect externally.
How is subnetting related to IP address classes?
Subnetting extends the class-based model by dividing a large IP network into smaller, structured segments. Adjusting the subnet mask lets administrators control how many subnets and devices each segment supports. This flexible approach prevents wasted addresses and improves network organization and security.
Why are IP address classes important?
The original class system shaped how IPv4 networks were organized and paved the way for subnetting, Network Address Translation (NAT), and private addressing. Even though it has been replaced by classless addressing, understanding the classes helps explain the logic behind modern network design.
Are IP address classes still used today?
Not anymore. Modern networks use Classless Inter-Domain Routing (CIDR), which allocates addresses by prefix length rather than fixed classes.
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN